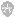第一,Fortran 的列优先是什么含义,与 C 语言有何区别?
Fortran 也好,C 也好,操作的数组都存在于内存中。而内存中是没有行列概念的。二维数组,三维数组,都是“一条线”一样的存储在内存中。在这个层面上,Fortran 与 C 没有区别。
不同的是,Fortran 和 C 会以不同的命名习惯来对内存中的数据进行“命名”,并通过各自的习惯来寻找对应的地址。
下图是一个范例。内存中存储了 8 个数据:1,2,3,4,5,6,7,8(蓝色框)。
他们对应内存中的地址,可能为 0x0041F100 , 0x0041F104 , 0x0041F108 ...... 一直到 0x0041F11C。这些地址是采用十六进制表述的,且只是假设,真实的地址会与他们类似。由于绝大多数 32 位编译器的整数和浮点数,都占有 4 个字节,因此,这些地址之间各相差 4 字节。(如无法理解本段落,问题也不大)
高级语言通常不会直接访问内存地址,所以 Fortran 和 C 使用数组来“命名”这些内存地址,并且通过数组+下标来访问这些内存地址。
如果把这一段内存地址视为 8 元素的一维数组,Fortran 和 C 的规则差别不大,Fortran 默认以 1 开头,而 C 则以 0 开头。
如果把这一段内存地址视为 2*4 元素的二维数组,则 Fortran 和 C 还有另一个差异:
Fortran 会先变化前面的维度,即顺序为 a(1,1) , a(2,1) .... 前面的 1 先变化为 2,后面维度始终保持为 1。直到循环完毕后,再将后面的维度加一,即 a(1,2) , a(2,2).....
C 语言则相反,会先变化后面的维度,即顺序为 a[0][0] , a[0][1] .... 后面的 0 先变化为 1,前面维度始终保持为 0。直到循环完毕后,再将前面的维度加一,即 a[1][0] , a[1][1].....
因此,对于二维数组来说,Fortran 的 a( m , n ) 默认情况下,对应于 C 语言的 a[n-1][m-1]。如果读者做两者的混合编程,这一点很重要。
不管如何“命名”和“取值”,内存中,始终是8个数据“一条线”排列着,内存中没有行,列的概念!实际上,如果不书写出来的话,二维数组本来也没有统一的行列概念。a( m , n ) 你可以把 m 叫做行而把 n 叫做列,也可以把 n 叫做行而把 m 叫做列。
但是,为了人们交流的方便,大家习惯上,把前面的维度称为列,后面的维度称为行。由于 Fortran 命名时先改变前面的维度,因此,人们习惯称之为 “列优先"
另外,Fortran 允许对整个数组进行操作。如果代码书写为: write( * , * ) a 或 write( * , * ) a( : , : ) 则编译器会按照上图的顺序来输出 a 数组。这也是 列优先 方式的表现。
第二,文件的行列,与二维数组的列优先之间有何关系?
这里的文件,指的是文本文件。一般文件可分为文本文件和二进制文件(实际上前者是一种特殊的后者)。而二进制文件也没有行列的概念。
文本文件面向人类阅读,所以存储时,根据人类的习惯,看起来存在行,列的概念。比如,上面的例子,可以存储为:
1 2 3 4
5 6 7 8
这样两行,每行四列数据。
虽然 Fortran 有列优先的规定,但这并不要求数据文件也一定是这样存储的。列优先,并不意味着必须按这个顺序来操作。只要有下标,就可以对数组元素操作。
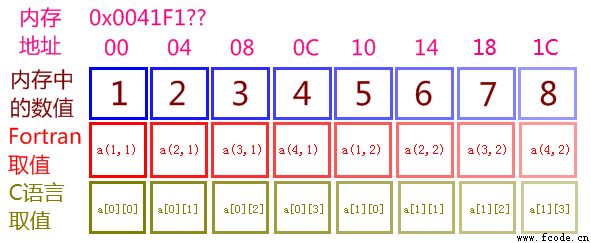
读取上述两行四列的文件,我们可以用这样的方式:
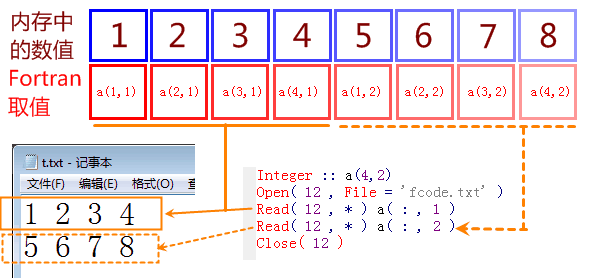
在不特别指定的情况下,每一个 read 语句读取一行。文件的读取,只能按行来,不能先读第一列,再读第二列。
上面的图,代码里书写了两个 read 语句,第一个读第一行,第二个读第二行。(通常写为循环)
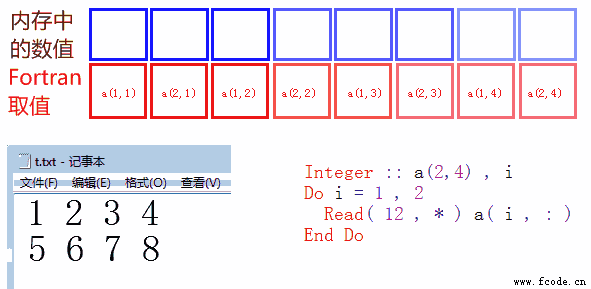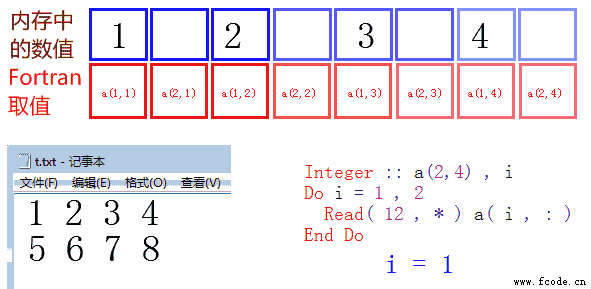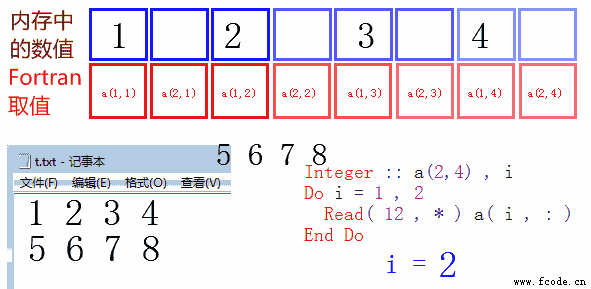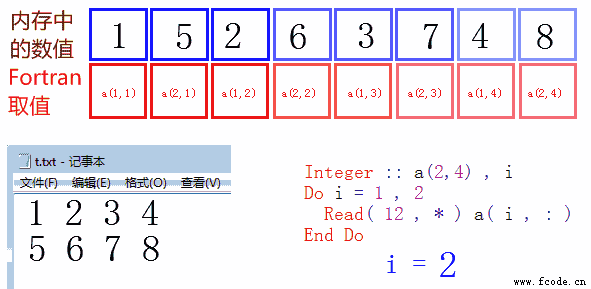
第一次读取第一行,存入 a( : , 1 ) ,这是 Fortran90 的新语法,表示后面的维度为1,前面的维度为全体。在本例中,他表示 a(1,1),a(2,1),a(3,1),a(4,1) 四个数。
第二次读取第二行,存入 a( : , 2 ) ,表示后面的维度为2,前面的维度为全体。在本例中,他表示 a(1,2),a(2,2),a(3,2),a(4,2) 四个数。
文件中的存储顺序与内存顺序是一致的,这是比较正常的读取方式。
如果文件是四行两列存放的。比如:
1 5
2 6
3 7
4 8
我们依然可以按照之前的 “列优先” 方式来读取并存储它。
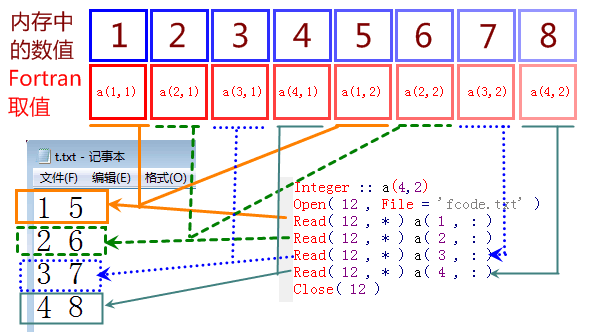
这里写了四个 read 语句,每个读取其中一行。(通常写为循环)
第一次读取第一行,1 5 两个数,存入 a( 1 , : ) 它表示前面的维度为1,后面维度为全部,本例中表示 a( 1 , 1 ) , a( 1 , 2 ) 两个数。
后面的三次读取以此类推。
可以看出,尽管文件里行列不同,但我们都可以通过改变代码而读取为相同的数组a(4,2)。
下面是一张动态图,便于读者理解。i=1 和 i=2 时,程序分别读取了第一行,第二行,存入内存(注意 a( i , : ) 的含义)。
第三,关于效率
尽管读取文件,操作数组等都有灵活的方式。理论上,只要指定下标,就可以操作数组的任意元素。但是,这依然涉及到效率问题。
在同一次循环,或者同一个 read 语句中。如果读取到的内容存入相邻的内存地址,效率会更高。而如果存入的是分隔开的内存地址,则效率会偏低一些。
例如第二点中列出的三张图片。显然,第一张图片的读取方式效率更高。第二张和第三张图片效率偏低。
再比如以下两个双重循环:
!// www.fcode.cn
real :: a(3,3)
integer :: i , j
!// 第一个循环
Do i = 1 , 3
Do j = 1 , 3
a(i,j) = 1.0
End Do
End Do
!// 第二个循环
Do i = 1 , 3
Do j = 1 , 3
a(j,i) = 1.0
End Do
End Do
虽然都是操作同一个数组,后一个循环效率会比前一个循环效率高。(不考虑编译器的优化作用)因为后一个循环,内循环时操作的三个数在内存中是相邻的,其寻址更方便。
我们在书写代码时,如果要循环对二维或更高维度的数组进行操作,尽量把前面的维度写在内循环,后面的维度写在外循环。这样可以提高优化后的程序执行效率。
PS:如果数组本身很小,就没什么必要了。另外,循环次数较多的循环,也适合放在内循环。这需要综合考虑
最后,Fortran在数组操作上具有优势,可对数组整体或片段进行操作。例如上面的代码,可简写为:
a( : , : ) = 1.0
或直接写为: a = 1.0
希望大家能有所收获!