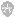严格地讲,堆栈是两部分:堆(Heap)和栈(stack)。但大多数时候,人们说堆栈,都指的栈(stack)。
本文描述的堆栈,也只是指栈(stack)。
简单的说,stack 是内存的一部分。因为CPU指令里有一大堆直接对堆栈的指令操作,所以,它虽然在内存里,但可以比其他内存空间有更快的读取写入速度。
在常规的语句执行时,CPU会优先读写寄存器(register,但是它容量很小),然后优先读写堆栈(stack,它比较小),最后才优先读写常规内存(它比较大),而再大量的数据,就放入硬盘文件(它非常大)。

这就好像,我们总会把最常用的东西(比如手机、钱包)带在身上,甚至揣在兜里(就像CPU读写寄存器一样)。而把比较常用的东西(比如耳机、充电宝)放在随身的书包里。最后特别不常用的东西会放在家里。
再比如,我们在办公的时候,最常用而且小巧的东西(笔、电脑、订书机)放在桌面上(就像寄存器),而较常用而且不太大的东西(文件、书籍、合同)放在抽屉里(就像堆栈),不常用或者非常庞大的东西,则放在仓库里(就像常规内存或者硬盘)。
二.堆栈有什么作用?
在绝大多数的平台上,堆栈主要完成这么四个事情:
1. 临时数据存放。
主要通过 push 和 pop 两个指令完成(什么?你不知道这两个指令?这没关系,书写高级语言代码不需要知道它们)。这就好比,我们在工作的时候,手边临时拿不了的东西,先暂时放在桌子上,等手头空闲下来了,再移动到该存放的地方。
2. 存放函数局部变量。
3. 存放函数的虚参。
第2和第3,我们举例来说(这部分看不懂也没关系),如下的函数调用:
call sub( a , b , c ) subroutine sub( a , b , c ) integer :: a , b , c real :: xx , yy , zz , sum end subroutine sub
调用了 sub 函数,并传入三个参数:a b c,函数有4个局部变量 xx yy zz 和 sum
在调用函数时,堆栈内的情况大概会是这样:
要看懂这个图,我们需要先了解两个寄存器:ESP 和 EBP。如果你不想了解,也可以直接跳过本段阅读。
ESP (extended stack pointer)寄存器用于记录当前堆栈的顶部位置。而 EBP (extended base pointer) 寄存器用于记录当前堆栈的基准位置。
在调用前,ESP 位于图中 C 上面 的位置(棕色区域),首先程序会把参数 a b c 放入堆栈里。然后把当前函数返回以后的地址放入堆栈里(EBP+16 到 EBP )。之后,放入当前的 ebp(以便函数调用完成后恢复它),之后会把ESP 继续向下移动,以便给局部变量(xx yy zz sum)腾出空间(EBP-4 到 EBP-16 )。
(题外话:由于局部变量的空间是“腾出来”的,故而我们可以理解,为什么每次进入子程序,其局部变量的值都是“随机的”,因为他的值,是上一次堆栈使用过后的残余。他可能是上一次调用某个函数时留下的其他局部变量,也可能是上一个函数的返回值或虚参。总之,他的值非常不确定!)
当调用结束后,程序会跳转到“返回地址”,恢复 EBP。最后再把 ESP 调回到棕色的区域。此时,EBP+16到EBP-16的位置并没有变化,也没有被回收。而是下次调用其他函数时直接覆盖。
4. 记录调用轨迹。
稍大的程序一般是一个函数调用另一个函数,然后再调用其他函数......为了能够让函数执行后按照原先的顺序返回,堆栈就必须记录调用的轨迹。(你可以试想一下一个走迷宫的人,如何记录自己走过的地方?)
以下是一张示意图:
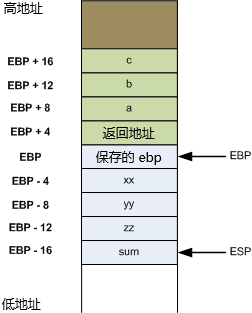
在主程序里,调用了 sub1 这个函数。在堆栈里,记录了 sub1 这条轨迹(实际上,这里面包含主程序对sub1的参数,返回地址,EBP和sub1 的局部变量,这些可以参考堆栈的第2和第3个作用,即上一张图)
同时 eip 指向 call sub1,说明当前执行到此处。而 esp 指向堆栈里的 sub1 这条轨迹,说明堆栈顶部在这里。
当 sub1 调用了 sub2 时,在堆栈里,向上堆叠了 sub2 的轨迹(实际上,也包含参数,返回地址,EBP和sub2的局部变量)
当 sub2 调用了 sub3 时,继续向上堆叠 sub3 的轨迹。
执行完 sub3 和 sub2,按照堆栈里记录的 sub1 的返回地址,返回sub1。然后向下执行 sub4,堆栈里 sub2 的轨迹被 sub4 的轨迹替换。而 sub3 的轨迹虽然还在,但由于堆栈顶部指针(esp)在 sub4 的位置,所以它并没有生效(图中灰色显示)。
然后继续执行 sub4,遇到 write 语句,write 语句在语法里可以直接使用。但实际上,它也是一个函数(由编译器厂家书写),所以它也会留下一个轨迹(覆盖之前的 sub3 的轨迹)。
所以,堆栈里不停的记录着调用函数的轨迹,当这个函数返回时,堆栈顶部就向下移动,再次调用时,之前的轨迹被擦除重写。
由此可见,堆栈的这四个作用是非常关键的。它在程序运行时,非常重要,不可或缺。
三.堆栈为什么会溢出?为什么会失衡?
那么,堆栈为什么溢出呢?这主要分两种情况:1.堆栈确实稍微有点不够。2.堆栈的需求太过分。
(这很容易理解,桌子放不下了,可能是桌子有点小,也可能是你把应该放在仓库的东西放在了桌面上)
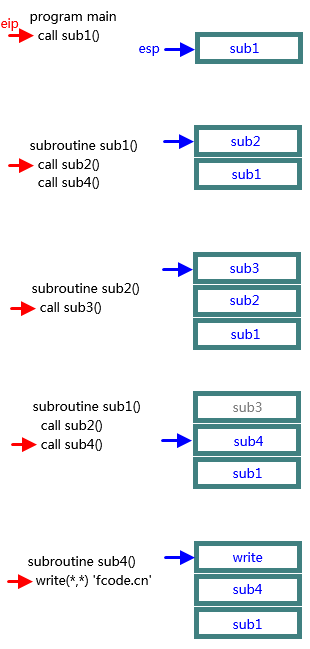
对于第一种可能,我们一般通过调整堆栈大小来解决。不同的编译器有不同的调节方法,VS 下可设置工程属性:
这里的单位是字节,所以图中的 1000000000 表示 1000MB,在32位系统上。这个值默认一般是 10MB,可以调节的范围是 10MB 到 1000MB,到 1000MB 还依然堆栈溢出的话,就要考虑是不是第二种可能了:
从上面,我们知道了堆栈的作用,自然就不难得出,堆栈要求太高而导致溢出的原因:
1. 需要临时存储的信息太多了(由作用1)。这种情况多发生在用内部函数(例如 max 、read、数组整体赋值 )处理较大量的数组。这种时候,我们可以用循环来代替一些内部函数,或者用循环分批次地处理内部函数。
2. 函数局部变量太大(由作用2)。局部变量多数存储在堆栈里,当它很大是,就容易溢出。尤其针对数组大小由虚参给定的情况:
subroutine mysub( n )
integer
real :: a( n )
这里的 a 往往会因为实参 n 非常大而导致堆栈溢出。这种时候,我们只需要用可分配数组来代替 real :: a(n) 就可,因为可分配数组一般放入 Heap 或其他内存空间。
3. 虚参太多(由作用3)。由于 Fortran 默认是传地址的,每个虚参都是一个地址(32位、4字节),并不大,所以即便虚参真的很多,通常也不会造成堆栈溢出。除非你指定了传值(value修饰)。
4. 调用轨迹太多(由作用4)。这通常发生在极其庞大(上万行代码)的程序里。对于这种情况,没有很好的解决办法。有一种特殊的情况,就是“递归调用”:我们知道,递归调用是函数自个调用自个,如果对递归的终止条件控制得不好,就会出现“调用轨迹”无限地堆积下去,造成堆栈溢出。
根据我们的经验,第2种情况发生的几率最高。其次是第4种情况的递归调用。
此外,堆栈除了会溢出,还可能会失衡。失衡一般发生在调用了函数库、调用了动态链接库、混合编程时。由于不同的函数库、不同的动态库、混编语言之间,函数调用时对堆栈的利用方式不同,而导致错误地使用了堆栈信息。
(专业地说,这叫“调用协定”)以上面的例子而言 call sub( a , b , c ) ,Fortran 传递虚参时,会按 c b a 的顺序传入堆栈,而有的语言则会以 a b c 的顺序从堆栈取出。返回地址、保存ebp的方式也可能有差异。就可能导致诸如这种错误:“把一个本应该是虚参的量,当成了返回地址,而无法正确的返回,而在堆栈里引发错误”
这一类的错误,统称为堆栈失衡。当发生这类错误时,就需要认真检查不同语言之间的调用协定是否一致,传址和传值是否相同等等这些规定了。
四.如何有效的利用内存?
这是一个复杂而不得不面对的一个问题。堆栈不够用,我们应该想办法把较多的数据放入常规内存。那么,如果常规内存依然不够用呢?我们还可以考虑把所需的数据分段使用,其他暂时不用的部分写入文件来存放。
正如一部MKV的电影,3.0GB,播放时并不需要占用 3GB的内存。
正如腾讯有几亿QQ用户,而服务器上并没有几亿大小的数组。
简单通俗的说,我们要学会的,是该把哪些东西拿在手里、哪里东西放在兜里、哪些东西放在家里、哪些东西放在办公桌、哪些东西放在仓库里。
即能让自己需要它的时候最快速度获取到,又能让它不占用宝贵的空间。