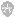注意,预处理只是简单的对源代码文件进行替换,与 Fortran 的语法并没有直接关系。预处理的结果,才是真正的 Fortran 源代码,并交给编译器编译成二进制的目标代码。这个过程大概如下图:

(有些编译器和预处理器在一体,因此,可能不会产生物理的 *.f90 文件,而直接产生可执行代码,但我们仍然可以按照上图来理解。)
然而,Fortran 语法中,并没有规定任何预处理的内容。因此,一部分编译器扩充了自己的预处理语句,也有一些编译器使用了现成的 C 语言的预处理器,于是继承了 C 语言预处理的写法。
本文会介绍一部分的预处理语句,但并不能保证他们能在读者的编译器上使用。请读者阅读自己使用的编译器帮助文档,以便了解该编译器支持的预处理语句和使用方法。
一. 常见的预处理器
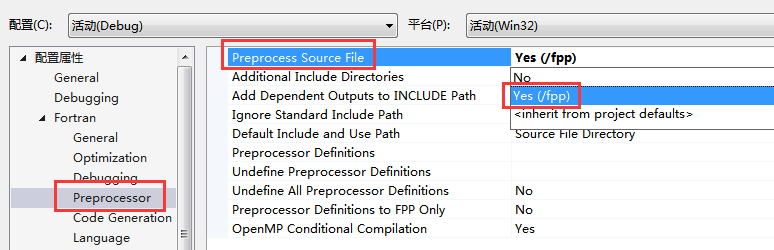
在 GNU 的编译器(gfortran)上,通常会使用预处理器 fpp (缺省调用、常用)或 C 语言预处理器 cpp(注意这里的 cpp 意思是 C Preprocessor 而不是 C Plus Plus)。
默认情况下,如果源代码的扩展名为大写(即 F90 , F , F95 等),则会将预处理器应用在该源代码上。
在 Intel 编译器上,除了可以使用 fpp 外,还可以使用 !DEC$ 等编译器指令来实现部分预处理。
(使用 fpp 时,需要专门指定编译选项 /fpp,如未指定,会收到一条警告:warning #5117: Bad # preprocessor line)
二. 宏定义
宏定义,是在程序中实现定义好一些宏观参数,以便在程序代码里统一使用,减少修改量。
例如,如下代码:
#define N 3
Program www_fcode_cn
Implicit None
real :: a(N) = 1.0 , b(N) = 2.0
integer :: i
Do i = 1 , N
write(*,*) a(i) , b(i)
End Do
End Program www_fcode_cn
它定义了 N 这个预处理常量,并让它为 3,则预处理器会讲代码中所有 N 这个 token 替换为 3。注意必须是单独的 token,例如:real :: sN 并不会替换为 real :: s3 , 而 a = "number" 也不会替换为 a = "3umber"
所以上述代码经过预处理后,实际交给编译器的代码为:
Program www_fcode_cn
Implicit None
real :: a(3) = 1.0 , b(3) = 2.0
integer :: i
Do i = 1 , 3
write(*,*) a(i) , b(i)
End Do
End Program www_fcode_cn
但是,由于预处理常量的存在,使得将来 N 修改为其他数值,如 #define N 30 更容易。如果预处理常量的值,是单纯的数字,或有意义的数据类型。建议使用语法中的常量来代替预处理常量。例如:
Program www_fcode_cn
Implicit None
Integer , parameter :: N = 3
real :: a(N) = 1.0 , b(N) = 2.0
integer :: i
Do i = 1 , N
write(*,*) a(i) , b(i)
End Do
End Program www_fcode_cn
这样的好处是:对N进行了必要的约束,它只能是整型。并且它符合语法规范。只有当 N 不能用特定的数据类型来表达时,才需要使用预处理常量。在 IVF 的编译器上,也可以使用 !DEC$ DEFINE SN=3 来定义 SN 这个预处理常量,让它的值等于 3。但它并不能用于替换源代码中的 N,只能用在条件编译时的判断(例如 !DEC$ IF (SN==3))。
三. 包含文件 include
包含文件被大量应用在 C 语言头文件中。但 Fortran 本身并不需要子程序的原型,函数也使用(interface接口)而不是原型。module 用 mod 文件实现接口。所以,Fortran 并不需要头文件。
在较老的代码中,由于大量使用了 common 共享数据。因此,常常把 common 里的数据定义放入 include 文件。
包含文件其实非常简单,它完全等效于打开被包含文件,全选,复制,然后粘贴在 include 语句处。它只是一个预处理的语句,并不参与语法的任何编译,也没有 module 或其他语法那样复杂的逻辑关系。
被包含文件(如 inc.h)只是简单的用文件内容替换 include 语句,它可以是任何文件名和扩展名(如 .h 或 .inc 或 .par 或任何扩展名),只要它实际上是书写有 fortran 代码的文本文件。
此外,如果包含文件(如name.f90)是自由格式,那么被包含文件(如 inc.h)也必须是自由格式。如果一个是固定格式,另一个也必须是固定格式。
需要注意的是,由于被包含文件(如 inc.h)已经被替换到 name.F90 文件中。因此,它不能再被编译、参与链接。所以,它不必,也不能出现在工程、解决方案中。这是区别于“多文件编译连接”的。
四. 条件编译
在某些时候,我们可能需要同一套代码编译出来多种可能的程序,分别适应不同的情况。例如,可以编译出中文版和英文版。
#define ENGLISH Program www_fcode_cn Implicit None #ifdef ENGLISH write(*,*) "Hello,world" #else write(*,*) "你好,世界" #endif End Program www_fcode_cn在这个代码中,首先用宏定义定义了 ENGLISH,然后用条件编译,指定了如果定义了 ENGLISH,则编译第5行代码,否则编译第7行代码。
这个代码会编译出一个英文版程序,如果读者试着删掉或注释掉第一行,那么会编译出中文版的程序。
条件编译很多时候容易与语法中的 if else end if 混淆。我们需要从概念上区分两者:
1.条件编译是预编译语句,由预编译器选择其中一个参与编译。而另一个不参与编译(甚至另一个可以是写法错误的),最终的可执行程序里,只包含一个分支。
2.if语句是执行语句,由编译器对两个分支都进行编译,都包含在可执行文件里,在执行时根据情况选择执行哪条分支。(它必须保证所有分支都是正确的)
通俗一点讲,我们可以这样理解:有的软件,中文版和英文版需要分别下载。那么它就是通过条件编译产生的两种版本的程序。而有的软件,可以在界面上随时切换中英文,那么它就是通过 if 语句得到的两种分支。
上面的例子,也可以用 ivf 的 !DEC$ 预处理指令实现:
!DEC$ define ENGLISH Program www_fcode_cn Implicit None !DEC$ if defined (ENGLISH) write(*,*) "Hello,world" !DEC$ else write(*,*) "你好,世界" !DEC$ endif End Program www_fcode_cn
总体来说,if 语句比条件编译更灵活,可以让用户自由选择,但设计起来更复杂。很多时候甚至需要大量的开发。
在跨平台的代码里,经常会用到条件编译。例如,如果宏定义为 Linux,那么执行 file >/dev/null ,如果宏定义为 windows,那么执行 file.exe >NUL
由于windows里的一些写法可能在linux下是不正确的,而 if 语句会编译所有分支,并且要求所有分支都是合法的。我们就只能使用条件编译来区别二者了。
我们鼓励读者:
1.使用条件编译来增加代码可移植性,但如果能用 if 语句代替,也是更好的。
2.建议尽量使用 parameter 常量,而不使用预处理常量。
3.include 语句除非在使用函数库时使用,其他时候应该尽量避免。
关于预处理指令,除了上面介绍的常用三种外,不同的编译器环境下,还有更多的用法。请读者朋友自行阅读编译器帮助文档了解。