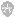另外,几乎没有程序员可以保证自己的程序一定没有运行时错误。因为运行时错误可能发生在某些特定的情况之下,而不一定是每次都会发生的。
例如:一个程序大多数时候跑得没有问题,突然有一天遇到内存占用很大,一块数组申请失败;或者忽然有一天,用户的磁盘满了;再或者,用户把一个具有只读属性的文件指定为输出文件;还有杀毒软件的一些拦截行为也可能导致某些操作意外失败。就计算程序来看,程序可能认为某个曲线是单调的,或者光滑可导的,某个数组的数据一点是大于 0 的,某个方程一定是有解的,但实际上用户输入的算例并不一定满足这些条件。
因为用户运行程序,是在未知的计算机环境,未知的算例进行的。因此,很多意外的运行时错误我们很难预料。即便是非常商业化的程序,如 QQ,迅雷,Internet Explorer,Visual Studio,甚至我们使用的编译器自身,出现运行时错误意外终止都不是新鲜事。
我们需要做的,恐怕只是尽量的避免运行时错误,使程序在绝大多数情况下可以正常运行计算出结果。此外,不是所有的运行时错误都需要修改代码,有些还需要调整输入文件,或者改变其他运行环境。(当然了,改变代码使得程序能更宽泛的适应多种特殊情况更好)
Q2001: floating invalid / math error / DOMAIN error / Integer divide by zero
原因:这是计算时最容易发生的错误,他表示浮点数错误,数学函数错误(如超出数学函数的定义域,负数开方,分母为零等等)。
解决:对数据进行合理控制,判断是否在定义域内,如每个算例均出现,应进行 Debug 调试。
Q2002: Program Exception - array bounds exceeded / Subscript #1 of the array A has value 101 which is greater than the upper bound of 100
原因:这是数组越界,即,数组引用的元素超出了定义它的范围。比如定义 a(50:100),如引用 a(49) 或 a(101) 则会越界。很多时候,这是循环对数组操作时,没控制好,比如 Do i = 50 , 100 然后引用了 a(i+1),当i=100时,i+1=101,就会越界。Intel Fortran 的数组越界会给出很详细的错误提示,包括具体越界的数组名,定义范围和引用角标。
解决:检查越界数组,根据情况修改代码。
Q2003: End-of-file during read
原因:这是读取文件时遇到了文件的结束。例如,代码要求数据有3行数据,而实际输入文件只有2行。在某些时候,甚至输入文件根本不存在或是空白文件。此外,数据文件缺失某些行某些列也是较大的可能。当然,也可能是循环读取文件时没控制住。比如想读100行,结果写错了,读了1000行。有时候,可能是文件路径错误,导致实际读取了另一个空白的文件。或者文件扩展名被隐藏了,比如读取 a.txt,但实际的文件名却是 a.txt.txt
解决:补足数据文件,或者修改代码使得读取的数据与实际数据文件一致。
Q2004: File not found
原因:这个就简单了,文件找不到。最大的可能是文件名写错了,路径(文件夹)放置不正确。
解决:增加应有的文件,或放置到合适的路径下。
Q2005: Attempt to access non-existent record
原因:一般针对直接读取文件,意思是读写了一个不存在的记录。例如文件只有2个记录,却视图读取第3个。也可能是记录长度的字节数设置不正确,使得应该在第2记录的字节超出了文件的字节。
解决:修改代码或修改文件,使得记录长度与个数相匹配。
Q2006: Insufficient virtual memory
原因:程序试图访问一个受保护或不存在的内存地址。多数为可分配数组,指针等动态内存引发的错误。
解决:确保数组已经经过分配后才访问,确保指针指向可用的内容。
Q2007: Format syntax error at or near x x
原因:在 x x 位置或附近的格式符 x 错误。因为使用了错误的输入输出格式符。
解决:修改源代码中对应的格式符,或输入正确的可识别的格式符。
Q2008: List-directed I/O syntax error
原因:输入数据不正确。例如从文件或字符串中读取整型或浮点数数据,而遇到非数字的符号,比如“abc”
解决:这个问题多数需要修改输入文件。
Q2009: Stack overflow
原因:堆栈溢出。可能性较多:堆栈不够;程序内局部变量太大或太多;递归调用终止失控。
解决:首先尝试改大堆栈,在不同编译器上具体操作不同。VS 下可设置工程属性,如图:
命令行下增加链接开关 /STACK:1000000000,1000000000
如果还是不足,可将大的局部数组改为可分配数组。如有递归调用函数,检查其终止条件是否设置合理。
Q2010: Program Exception - access violation
原因:这个问题可能性很多,属于比较麻烦的运行时错误。表示程序尝试读写一个非法的内存地址。常见于可分配数组尚未分配就传入子程序使用,子程序中修改了虚参但对应的实参为常数。等等。
解决:Debug 调试,检查错误所在位置。
Q2011:Formatted I/O to unit open for unformatted transfers / Unformatted I/O to unit open for formatted transfers原因:使用无格式打开的文件,但使用了有格式的输入输出。或反之。
解决:使用匹配的格式打开和输入输出。
Q2012:Sequential-access I/O to unit open for direct access
原因:使用直接读写方式打开的文件,但使用了顺序读取的输入输出。
解决:使用匹配的读写方式打开和输入输出。
Q2013:Input conversion error
原因:输入时,遇到了异常的转换错误。可能是输入中包含非法的字符(比如输入一个整数,遇到了 1.7a3),或者输入数据超过了转换数据的范围(比如输入一个32位整数,但输入值超过了 2147483648)。
解决:修改文件,去除非法字符。或使用更长的变量类型容纳大数据。
IVF 的运行时错误官方有专门的文档,大约有700多个。这里无法一一列举。如果你遇到运行时错误,请先尝试翻译它。然后尝试去解决。CVF和其他编译器的运行时错误与这些类似但不完全相同。
四. 计算结果不符合预期
这是最麻烦的错误了。编译器和操作系统已经无法帮助我们来检查和预知错误。需要我们自己进行 Debug 调试,检查计算结果从哪里开始与我们的预期开始不同了。
如果你的代码在其他编译器或其他操作系统上可以正常使用,但更换编译器以后计算结果不正确,也不要觉得奇怪。语法只是规定了一部分规则,还有很多语法中尚未规定的事情,不同编译器的处理就不一样,导致这种结果。这恰恰说明代码还有隐含的错误。
一段严谨的代码,会尽量避免上述情况。我们在书写代码时,也应该如此。不要让代码离开你的计算机就变成一堆垃圾。
如果你遇到了计算结果不符合预期的情况,耐心的检查吧,以下可能会是突破点:
1.检查变量是否全部定义并给定了类型和精度。程序单元都使用了 Implicit None 语句。
2.检查变量是否有尚未初始化就使用的情况?
3.函数调用过程中,是否存在虚参实参的类型差异。
4.变量的 Kind 值在不同编译器上的含义是否有差别?
5.直接读取文件的 RecL 的值在不同编译器上含义是否一致?
6.是否使用了依赖编译器的函数库,在更换系统后同样替代的函数,适用范围是否一样?
最后,强调一下,如果你使用的编译器不是 Compaq / Intel Visual Fortran 系列,他们的错误提示与本文的可能不同。请你首先尝试翻译错误提示,大多数情况错误提示会把问题描述得比较清楚。